キーワード検索

07|SCREENING|財務スクリーニングPythonツール
07|SCREENING
| 価格 | 7,800円(限定5部) |
| リリース日 | 2024年2月12日 |
| 最新バージョン | 1.2 |
| 分析対象企業 | 最新財務データセット エクセル掲載企業 |
| 必要財務データ | 3年分のBS・PL・CF |
| 手動データ入力 | 不要 |
| アップデート告知 | ザイマニ公式LINE |
最新財務データセットから好きな条件で企業を抽出できるPythonツール。自己資本比率60%以上かつROE10%以上など、自分なりのスクリーニング基準を持っているビジネスパーソンに特におすすめのツールです。
スクリーニングで抽出した企業群や各業種の上位企業群を対象に、指定した財務指標で差分をグラフ化することも可能。競合他社の比較分析シーンでも重宝します。
「優良企業を効率的に抽出したい・競合優位性をサクサク見つけたい」そんな方のためのPythonツールです。
07|SCREENINGの目次
07|SCREENINGのサマリー
07|SCREENINGの目次とアウトプットイメージは以下の通りです▼
また、今回使用するプログラミングコードは以下の3セクションで構成されています▼
0|ゼミデータセット読込
1|スクリーニング
2|差分抽出
3|オリジナル指標
セクション1は各種条件を設定し企業をスクリーニング。セクション2は抽出した企業群を対象に、最も差分のある財務指標のグラフを作成。そして、セクション3はオリジナルの指標を作成&スクリーニングする機能が搭載されています。
07|SCREENINGの使い方
情報・通信業の企業から様々な条件を設定し9社を抽出した事例をもとに、07|SCREENINGの使い方を解説します。
STEP
財務分析Python「07|SCREENING」をダウンロードする
STEP
初期設定を行う
上からひとつずつ、以下のコードまでセルを実行してください。財務分析ゼミメンバー限定で共有している最新財務データセットエクセルをアップロードするためのフォルダをGoogleDrive上に作成するコードです▼
# ゼミデータセットをアップロードするフォルダGoogleDrive上に作成する
zemi_dataset_upload_path = '/content/drive/MyDrive/Colab Notebooks/01_Zemi_Dataset' #ゼミデータセットをアップロードするフォルダのパス
os.makedirs( zemi_dataset_upload_path ,exist_ok=True ) #フォルダが存在しなければフォルダを作成
# Pythonツールのアウトプットを保存するフォルダをGoogleDrive上に作成する
python_save_folder_path = '/content/drive/MyDrive/Colab Notebooks/02_Python_Tool_Output'
os.makedirs( python_save_folder_path ,exist_ok=True ) #フォルダが存在しなければフォルダを作成上記コードを実行すると、あなたのGoogleDrive上に「01_Zemi_Dataset」など複数のフォルダが作成されます。
STEP
最新財務データセットエクセルをGoogleDriveにアップロードする
STEP
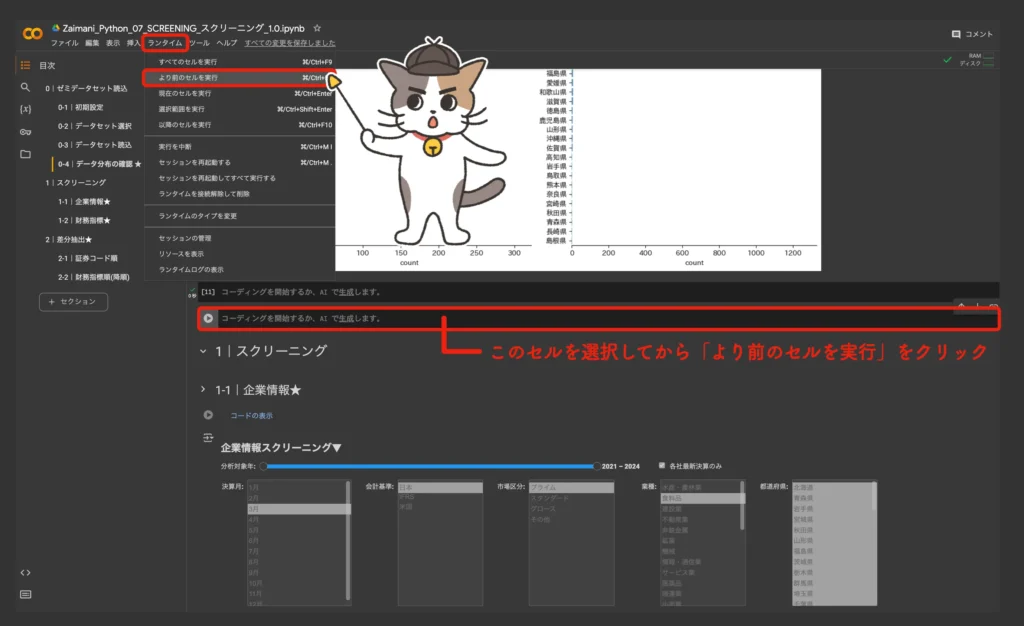
「1|スクリーニング」の直前までのセルを実行する
「1|スクリーニング」の直前のセルを選択し、画面左上のメニュー一覧 > ランタイム > 「より前のセルを実行」をクリックします。
STEP
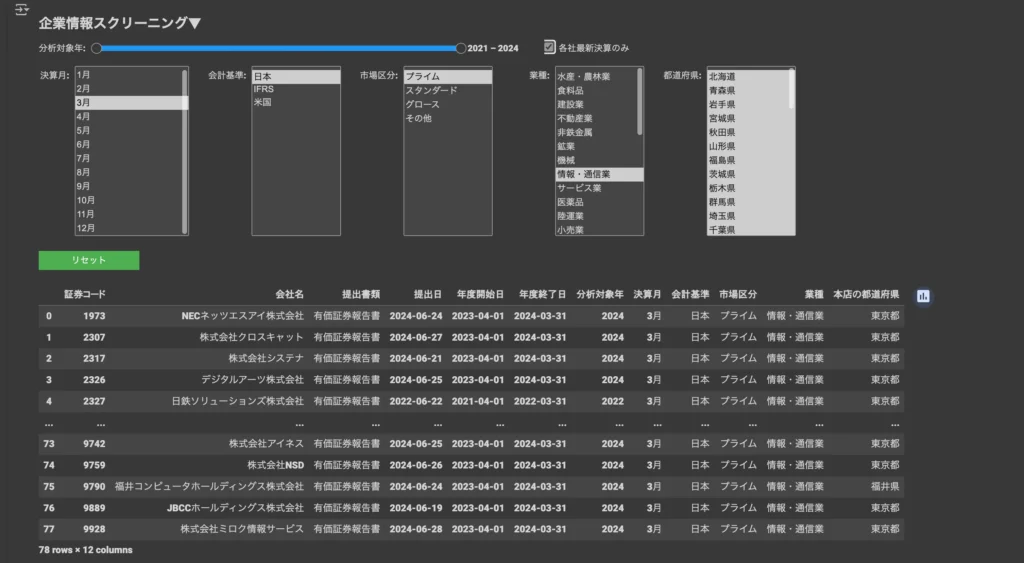
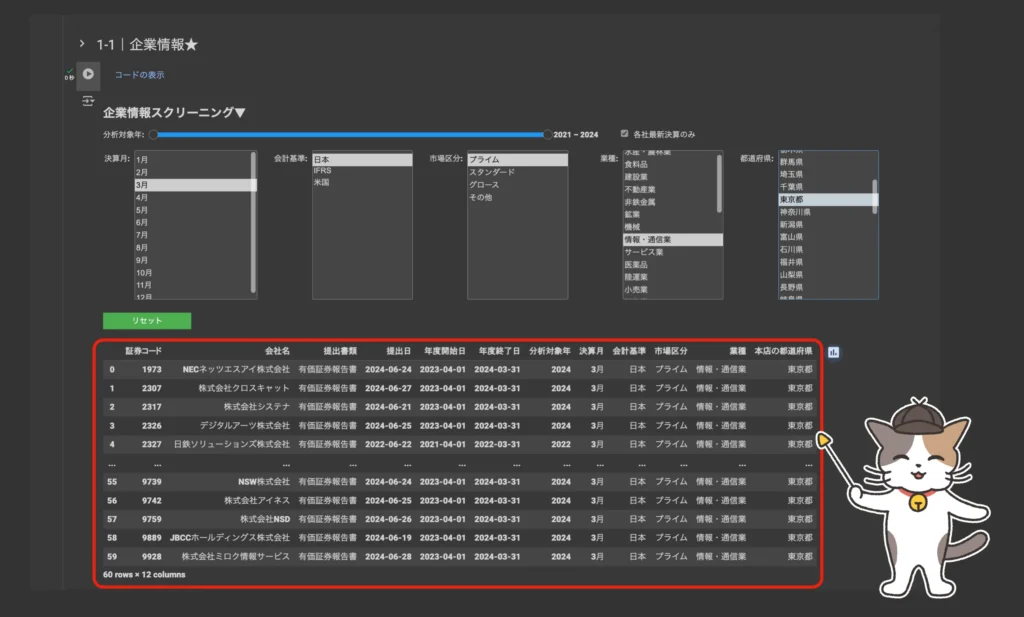
企業情報スクリーニングを実行する
コード実行ボタン「▶︎」を一度クリックします。その後、各種スクリーニング条件の設定が可能になります。command or ctrlを使用することで複数項目同時設定も可能(例:決算月が1月かつ3月)。
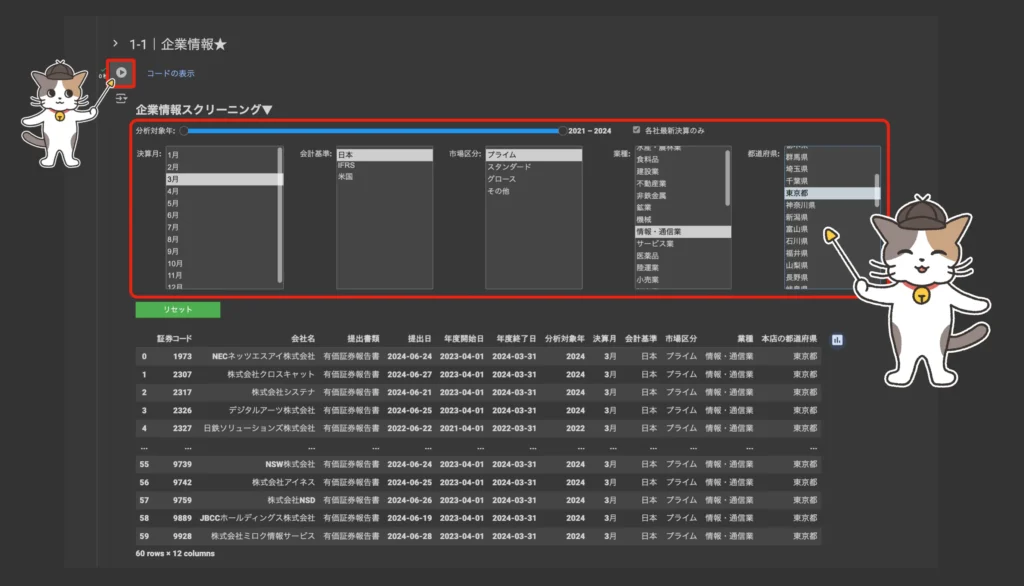
各種条件を設定すると同時にスクリーニングが実行され、直下のテーブルの絞り込みが自動的に行われます▼
STEP
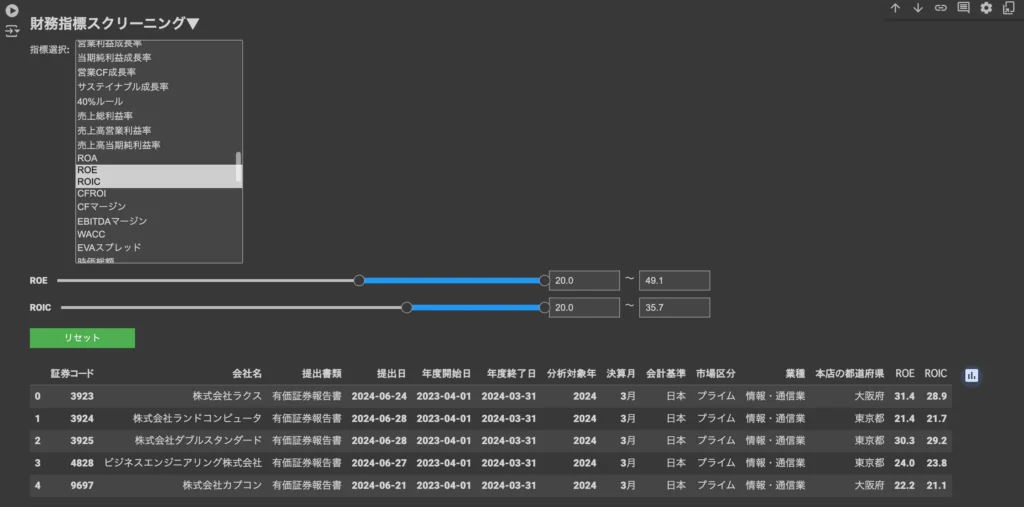
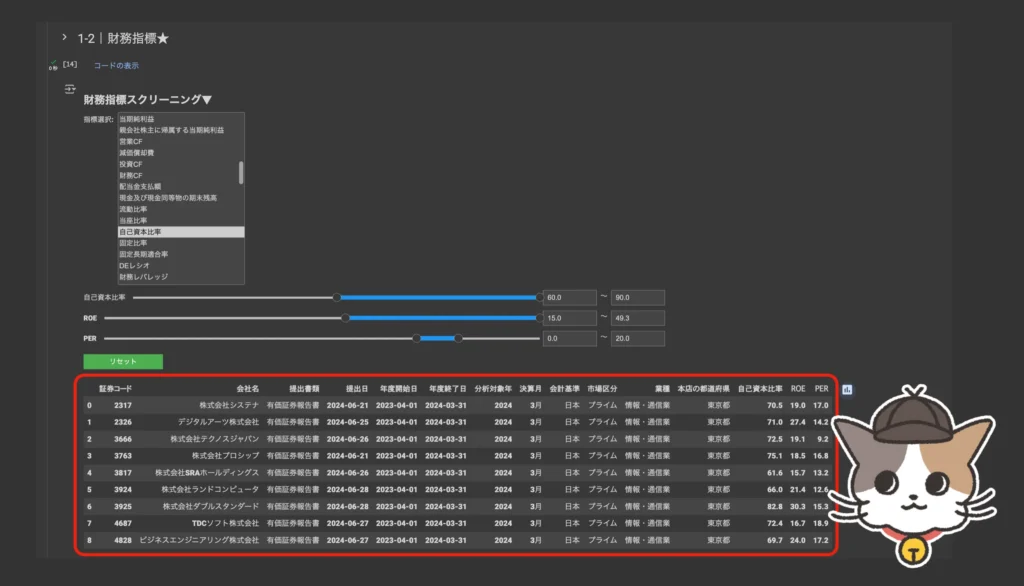
財務指標スクリーニングを実行する
こちらでもコード実行ボタン「▶︎」を一度クリックします。その後、財務指標のスクリーニング条件を設定しましょう。command or ctrlを活用することで複数指標の同時設定も可能です(例:自己資本比率とROEとPERの3指標でスクリーニング)。
その後、各指標のスクリーニング範囲を設定します(例:自己資本比率の最低値を60に設定)。スライダーの移動または数値入力どちらでも範囲設定を行えますが、数値入力の方が簡単でおすすめです。
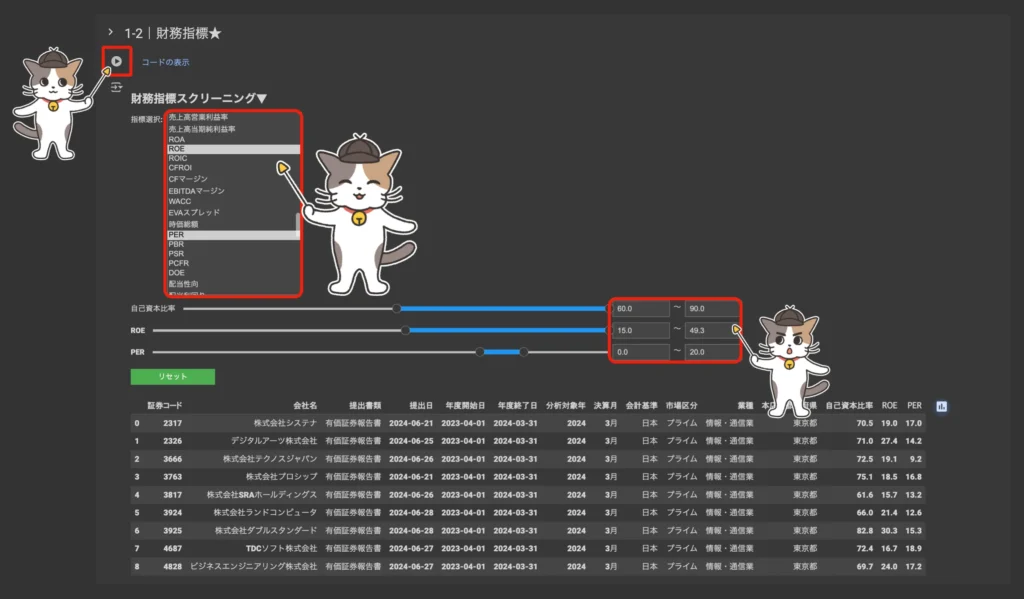
各種条件を設定すると同時にスクリーニングが実行され、直下のテーブルの絞り込みが自動的に行われます。ここでは9社を抽出することができました▼
STEP
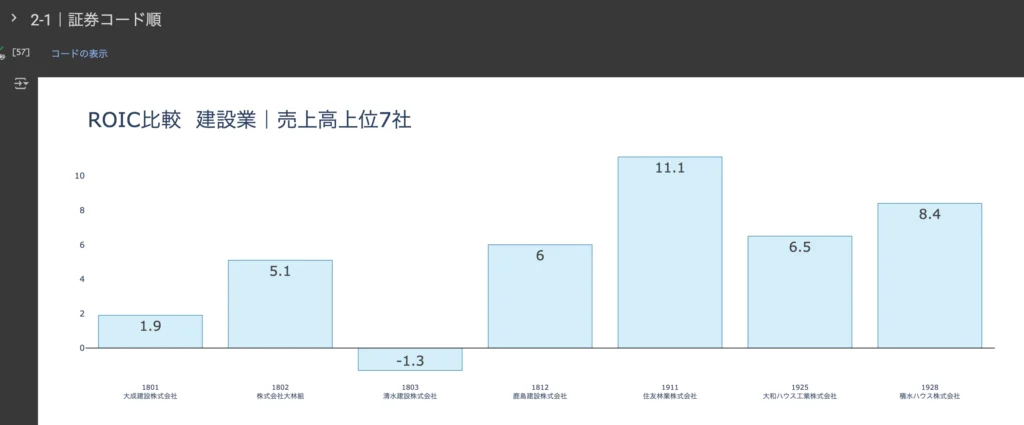
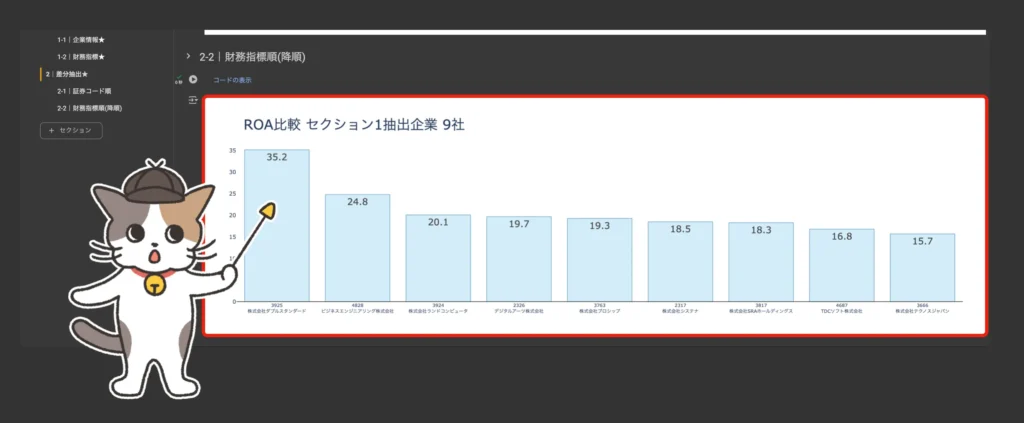
抽出した企業を比較する
セクション1で抽出した9社を比較します。以下のコードのハイライト箇所2点を注意して設定してください。
1点目はsection_one_comparison_flag。セクション1で抽出した企業を比較する場合’YES’、ゼミのデータセット全体を対象に0からスクリーニング&比較をスタートする場合は’NO’を設定してください。
また、2点目のtarget_financial_indicator_list。こちらは比較したい財務指標リストです。このリストの中から、対象となる企業群の中で最大値と最小値に最も差分のある指標が後続のコードでグラフ化されます。
#セクション1で絞り込んだ企業を比較する場合はYES, ゼミデータセット全体から抽出する場合はNO
section_one_comparison_flag = 'YES' # ★★★
if section_one_comparison_flag == 'YES':
target_company_num_list = filtered_df_for_save['証券コード'].tolist()
target_industry = ''
target_sort_item = ''
# ゼミデータセット全体から新たに抽出する場合、以下の項目を設定する
else:
# 特定の業種×特定の指標のトップ7社の証券コードを抽出する処理
target_industry = '建設業' # ★★★
target_sort_item = '売上高' # ★★★
num_companies = 7 # ★★★
# 業種でフィルタリングし、勘定科目で並び替え
filtered_df = df_company_comparison[df_company_comparison['業種'] == target_industry]
sorted_df = filtered_df.sort_values(by=target_sort_item, ascending=False)
# トップの企業の証券コードと会社名を抽出
top_companies = sorted_df[['証券コード', '会社名']].head(num_companies).reset_index(drop=True)
target_company_num_list = list(top_companies['証券コード'])
target_financial_indicator_list = ['ROA', 'ROE', 'ROIC'] ##指標の追加も可能 例:['ROA', 'ROE', 'ROIC', '自己資本比率'] # ★★★
print(target_company_num_list)STEP
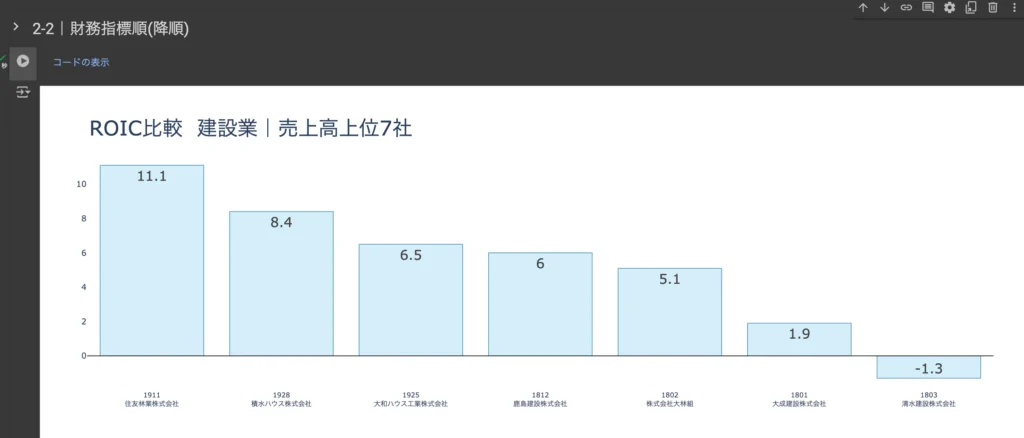
差分抽出グラフを表示する
コード実行ボタン「▶︎」をクリックしてグラフを表示する。
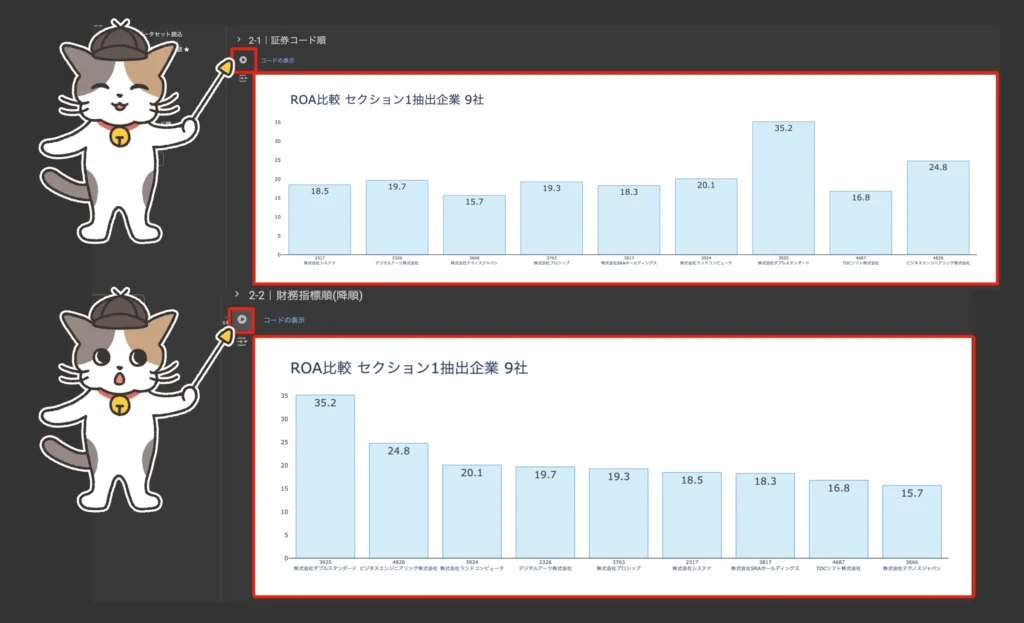
バージョン1.2からは自分の好きな指標を追加し、好きな条件で絞り込みができる「3|オリジナル指標」セクションを追加しました。簡単に使い方を解説します▼
自分の好きな指標を追加する
# ゼミデータセットに存在しない指標列を作成し、スクリーニングする
# 元データをコピー(ここに新規指標列を追加していく)
df_original_indicator = df_zemi_dataset.copy()
# 既存の項目リストを表示
existing_cols = df_original_indicator.columns.tolist()
print("既存の項目一覧")
for i in range(0, len(existing_cols), 10):
print(" " + ", ".join(existing_cols[i:i+10]))
print()
# オリジナル指標(新規列)作成 ★★★
df_original_indicator['売上高営業外収益率'] = df_original_indicator['営業外収益'] / df_original_indicator['売上高'] * 100
df_original_indicator['売上高特別利益率'] = df_original_indicator['特別利益'] / df_original_indicator['売上高'] * 100
# df_original_indicator # 列追加の確認ハイライト箇所の売上高営業外収益率や売上高特別利益率のように、新たに追加したい指標の計算式を記述することで、データセットになかった指標でも絞り込みができるようになります。
自分の好きな条件でスクリーニングする
# 絞り込み結果を表示する
# スクリーニング条件設定 ★★★
screening_conditions = [
"分析対象年 == 2025",
"会計基準 == '日本'",
"業種 == 'サービス業'",
# "売上高営業外収益率 > 10",
# "売上高特別利益率 > 30",
"一人当たり営業利益 > 20000000",
]
# 上記条件で絞り込んだデータセットを作成
df_original_screening = df_original_indicator.query(" and ".join(screening_conditions))
# 表示するデータセットの列を指定 ★★★
filter_cols = (
["証券コード", "会社名", "年度終了日", "分析対象年", "決算月", "会計基準", "業種"]
+ ["売上高", "営業利益",
# "営業外収益", "売上高営業外収益率",
# "特別利益", "売上高特別利益率",
"従業員数", "一人当たり営業利益"
]
)
# 上記条件で絞り込んだデータセットを表示 ★★★
# 特定の指標で昇順・降順を選んで表示可能 False:降順, True:昇順
df_original_screening[filter_cols].sort_values(by="一人当たり営業利益", ascending=False)ハイライト箇所を調整することで、自分の好きな条件で絞り込みができます。例えば上記は2025年の決算を対象に、会計基準が日本、サービス業に属する企業のうち、一人当たり営業利益が2,000万円以上の企業だけを抽出しています。
この機能をうまく扱うことで、自分だけの絞り込み条件を作成してスクリーニングを行うことができます。ぜひご活用下さい。
07|SCREENINGの分析例
以下の条件でスクリーニングを実践。9社を抽出した事例。
企業情報スクリーニング
・各社最新決算のみ:ON
・決算月:3月
・会計基準:日本
・市場区分:プライム
・業種:情報・通信業
・都道府県:東京都
財務指標スクリーニング
・自己資本比率:60%以上
・ROE:15%以上
・PER:15倍以下
最新財務データセットは以下を使用。
zaimani_zemi_dataset_until_20240831
07|SCREENINGの販売プラットフォーム
07|SCREENINGはクリエイタープラットフォーム「note」にて販売しております。
これはザイマニ管理人が個人で決済システムを構築・メンテナンスするよりも、上場企業が運営する大手プラットフォームを利用する方が主にセキュリティ面に優れ、ユーザーの皆様に安心して購入いただけると判断したためです。
また、07|SCREENINGの販売価格は以下のような要因によって変動します。正当な理由なく価格を釣り上げることは絶対にございません。
- Pythonコードのアップデートによる機能追加(ユーザーからのフィードバック反映など)
- 急速な為替変動に伴う開発コストの増加
07|SCREENING利用時の注意事項
- 本Pythonツールの譲渡・転売・貸与・再配布を禁止します。
- ご利用にあたってザイマニのクレジット表記は必要ありません。
- SNSやブログ等で分析結果画像を掲載される場合、出典としてザイマニを明記&リンクして頂けると嬉しいです。
- Google Colaboratory自体のアップデートにより、本Pythonツールが意図通りに機能しなくなる可能性がございます。その際は気兼ねなくザイマニ公式LINEかお問い合わせページからご連絡くださいませ。早急に対応いたします。
- 本Pythonツールのアップデート情報はザイマニ公式LINEで告知しますのでぜひご登録ください。
- その他の注意事項をまとめた利用規約をご一読の上、ご購入・ご活用くださいませ。
07|SCREENINGに関するお問い合わせ
購入前のご相談や、本Pythonツールをご利用中に不具合を発見された場合は以下のお問い合わせ窓口より気軽にご連絡いただけますと幸いです。
ザイマニのお問い合わせ窓口
財務分析図鑑
上場企業の分析結果を知る

財務分析ゼミ
noteメンバーシップでスキルアップする
